Service Fabric’s General Availability was announced at Build 2016 during Scott Guthrie’s keynote; where […]
Service Fabric’s General Availability was announced at Build 2016 during Scott Guthrie’s keynote; where Scott Hanselman demonstrated Age of Ascent’s live code showing how we used Service Fabric and the benefits it brings.

You can now also deploy it to AWS, on-premise, local as well as Azure as demonstrated by Mark Fussell and Jeffrey Richter in their Azure Service Fabric for Developers breakout session.
Service Fabric’s stateful services are out-of-the-box resilient and highly reliable in the face of multiple VM failures. Saying that, the levels of resiliency and durability of data can be increased, and that’s what we’ll run through below.
The default deployment template for Service Fabric uses the VMs’ fast temp drive for storage, which is stable across reboots+guest o/s updates. However, the temp drive isn’t stable across events that cause a VM migration, e.g. host o/s updates, host failures, VM resizing etc.
Luckily, that is also what Service Fabric replicates its state for, and why there is a primary – and multiple secondaries. The update and fault domains should prevent any standard data loss as long as you are using the recommended cluster size of 5 or higher.
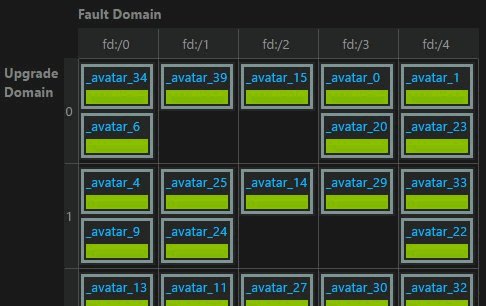
If you shrink your cluster to 3 nodes then the risks are higher; as if you have one node upgrade, and if a further node fails then you are out of quorum and down to a single node. With > 5 nodes you’d be down to 3 and still maintain a quorum. It also follows that more smaller nodes are better than fewer larger nodes.
Don’t forget the microservice data will also migrate between the nodes dependent of load and resource usage anyway, so it’s part of the system to deal with this.
Assuming you are at 5 nodes or above; for disaster recovery using temp drives in this replicated manner you need to consider what would cause this to be a risk – as it would need failure of at least 3 VMs for a 5 node cluster, and more for a cluster with a higher replica count.
Total outage of a datacentre is one circumstance, however it’s very rare and getting rarer as lessons are learnt. It has, however, happened – so can’t be discounted. A much more likely scenario is a capped subscription running out of $ balance, which will eventually de-provision the VMs.
Otherwise its likely to be manual intervention, e.g. manually shutting down and de-provisioning the VMs in the cluster. When you start it up again, the VMs will have migrated host.
Expected reboots/upgrades are handled via the upgrade domains; resilience is provided by the fault domains (and Service Fabric). If you want to further insulate yourself from Azure infrastructure issues, you can choose a “durability tier of Gold” and run your services on Full node VMs like D15 or G5. This allows the system to push back against any Azure infrastructure changes that cause migrations (with the exception of host failure) for 2 hours, allowing the replica set to build itself a brand new copy, if needed.
By default, Service Fabric uses the temp drive. However, you can override the location of the data folder default setting via ARM template deployment, to change the permanence of the storage with a performance/pricing trade off. You can also raise the reliability of the cluster through increasing the number of secondaries from the default of 3; though it needs to be an odd number for the quorum. The numbers of replicas you can choose are 9, 7, 5 or 3; also referred to as Platinum, Gold, Silver and Bronze respectively.

Using memory-only replication (not currently available) at Bronze level will give you general resilience over 2 VM failures (in 5 node cluster), and protection against unexpected reboots/migration – and fastest performance.
Using the temp drive SSDs (default) on D/Dv2 will give you the next highest performance drive, and will additionally survive a total cluster reboot.
To survive a total cluster failure/migration/data center outage; the next highest performance would be DS/DSv2 series using a custom ARM template with the data on multiple RAID’d premium storage drives – this is also the highest cost, due to premium storage being both charged by reserved space (rather than used space), and being more expensive than regular storage.
You shouldn’t use DS/DSv2 over D/Dv2 VMs unless you are using premium storage; as 86% of the local SSD is given over to premium storage cache whether you are using it or not; so they have a much reduced availability of local SSDs. e.g. D1 has 50GB of SSD, but DS1 only has 7GB with 43GB of premium storage cache.
The next highest perf would be with data on multiple regular storage drives RAID’d, then on a single data drive and finally on the O/S drive.
So, there is a performance/disaster recovery/pricing trade off to be made in this whole calculation.
Temp drive for data will be highly resilient and survive node outages and host o/s failures; however, there are some disaster circumstances where it won’t be enough, and it depends on your data.
Is adding periodic backups enough?
Do you want zero lost transactions (which may happen with backup) and are willing to take a perf hit and move to permanent storage; at various performance/cost levels. You can change the locations of the data and logs via ARM template deployment.
Also don’t forget you can have multiple node types:
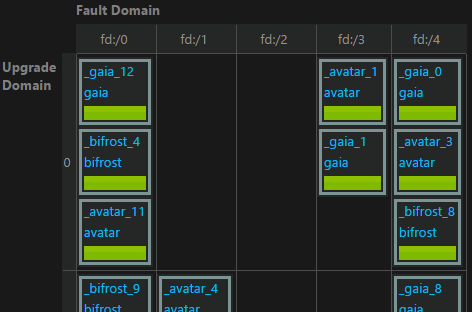
So you could have some on faster storage and some on maximum disaster-resilient storage; then use node constraints to say where the data is allowed to reside on based on how critical it is.

Get in touch!
For press: press@ageofascent.com.