Serving 6.8 million requests per second at 9 Gbps from a single Azure VM
At Illyriad Games we are building a new scale of gaming for Age of Ascent, an Ultra-MMO with real-time twitch combat at unprecedented scale. We also want an instant-on and always-updated experience rather than waiting for gigabyte downloads and patches; so we are eschewing conventional wisdom for high speed game clients and building it in javascript and webgl rather than C/C++ and DirectX/OpenGL. But that is a tale for another time…
Today we’re talking about server IO throughput at the extreme end.
In March 2014 we held a public scale test with 997 direct-piloting concurrent RL players in the same combat zone; and we later ran an automated load test which had a throughput of 267 million application messages per second using 748 cores which gave us substantially higher (simulated) player numbers.
However, technology marches on, and we were looking to revalidate our assumptions and design choices (which are a little unconventional, to say the least) – and see how things are today.
While our game servers are built more like HFT Quant trading servers, we also need to dynamically scale and repartition space on the fly based on demand. Our dynamic scaling needs are a good fit for the cloud where we only pay for what we use and always have more capacity ready for when we need it – whether burst or sustained.
For our high throughput needs, prevailing wisdom would suggest you need to write your server in C++, use UDP rather than TCP and run on a very high spec bare metal box running linux. We are already running the client in javascript; so if we ran over TCP (websockets), wrote the server code in managed C#, ran on Windows on a VM in the cloud – is this just madness?
The ASP.NET team have been testing experimental server designs in their Smurf Lab and recently moved it to a 10GbE network. We quickly created a http echo server based on similar principles to our game server networking; hoping to validate whether there was any inherent “cost” in using managed C# rather than a lower level, closer to the metal, language.
Kindly they agreed to test it: initial feedback was encouraging!
@ben_a_adams @davidfowl ok so perf is holy shit amazing. I'm going to make some comments on the PR of some things we'd love you to try :)
— Damian Edwards #GetVaccinated (@DamianEdwards) July 20, 2015
After some tweaking based on their feedback we managed to get a single server performing at 8.5Gbps peaking at 7.7million (7,765,336) requests per second (whilst at 50% CPU) – which they showed on their weekly ASP.NET Community Standup:
The code shown in the video can be found here.
While this is extremely good performance, it would be better if we had a base line to compare against. Luckily there are the TechEmpower benchmarks:
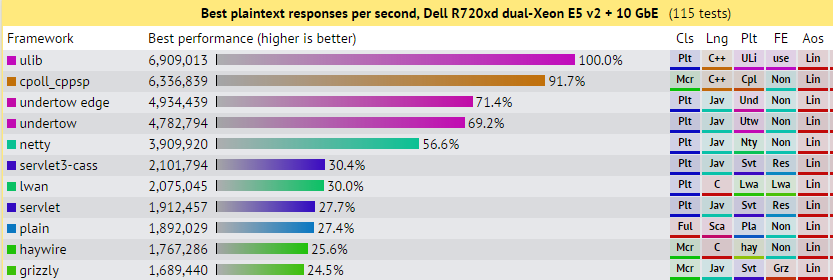
Looking at the two top performing servers ulib and cpoll_cppsp, both C++ on linux, we are doing really well!
However before jumping to any conclusions there are a few caveats.
The main one being we weren’t following the rules of the test: Test type 6: Plaintext.
After making some changes to meet the criteria of the test, the results are as follows:
| Connections | Pipeline Depth | Bandwidth | RPS | CPU |
|---|---|---|---|---|
| 1 | 1 | 25 Mbps | ~14k | 13% |
| 8 | 16 | 1.1 Gbps | ~855k | 37% |
| 8 | 512 | 7.3 Gbps | ~5.4m | 40% |
| 32 | 16 | 2.9 Gbps | ~2.2m | 80% |
| 128 | 16 | 6.0 Gbps | ~4.5m | 100% |
| 256 | 16 | 6.8 Gbps | ~5.1m | 100% |
| 512 | 16 | 6.9 Gbps | ~5.2m | 100% |
| 512 | 150 | 8.8 Gbps | ~6.7m | 84% |
| 512 | 512 | 9.1 Gbps | ~6.9m | 67% |
Again; very good and coming close to saturating the NIC!
After some additional changes to use SIMD which is now available in the v4.6 .NET Framework and hardware accelerated with the new RyuJIT compiler; well the results aren’t in just yet… hopefully it will bring down CPU and up network.
Again some caveats: what we are testing isn’t a full webserver, although it should pass the plain text requirements. However the others are full webservers – so are certainly doing more work per request. On the other hand, we were testing on a 6 core Xeon E5-1650 (12 HT cores) whereas the TechEmpower benchmarks are running on a dual Xeon E5-2660 v2 (40 HT cores). So 28 more cores to play with in the actual benchmarks? Of course, NUMA node and clock differences apply, so it’d be interesting to do a direct comparison.
At this point, I think we’ve concluded that Windows and C# can be very good in the high performance networking role… and possibly out-perform the best C++ on linux so far? Further, deeper tests will reveal whether this is true.
So, how does this translate to the cloud? Bearing in mind max TCP throughput, per connection, is bounded by latency, so two VMs connecting across a datacenter will perform worse than two machines next to each other directly connected via a switch. Equally, connecting from East Coast USA to East Coast USA will be a higher bandwidth connection than East Coast USA to Europe; ignoring terrible last mile connectivity and wifi packet dropping, for the same reason. Interestingly West US to East US is about the same as East US to Europe.
So, first things first; make sure Receive Side Scaling (RSS) is switched on in the Virtual Network adapter:
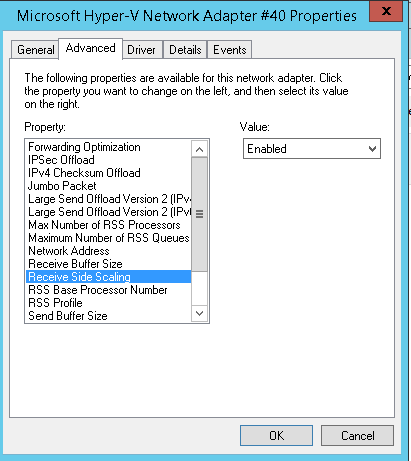
Not sure why this isn’t always the default, lower latency for low bandwidth situations? Trying the SIMD server on Windows with a linux wrk load generator; same test as earlier, on an Azure D4 VM (8 cores) – gives the following network and CPU:
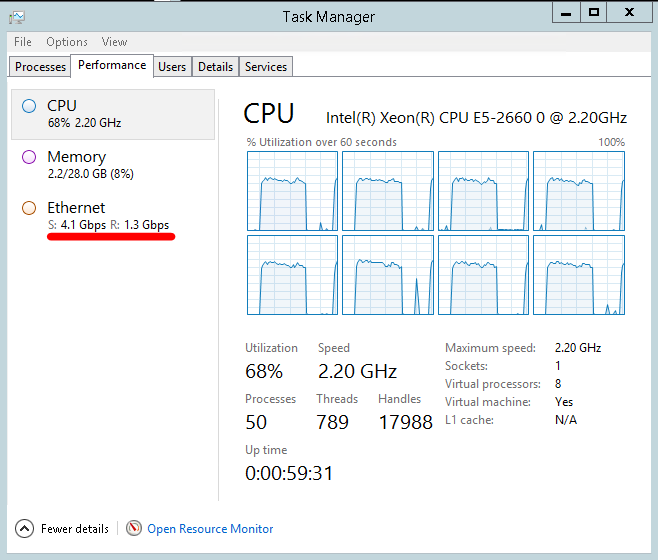
So the Windows VM is sending 4.1Gbps for 68% CPU which is very good bandwidth even for a bare metal machine let alone a VM, with plenty CPU to do other things. Looking at the linux measurements:
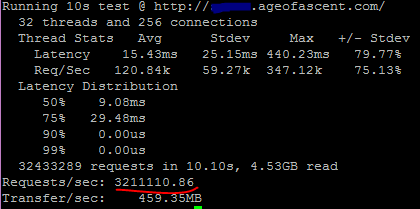
That translates to 3.2 million requests per second (3,211,110) – which is outperforming all but the top 5 on the 10 GbE directly connected 40 HT core Peak tests. Which is, again, exceptional performance. That’s a request every 311 nano seconds; or 0.3 micro seconds; or 3211 requests a millisecond.
Can we do a more like-for-like cloud comparison? Luckily, again TechEmpower provide some benchmarks here too:
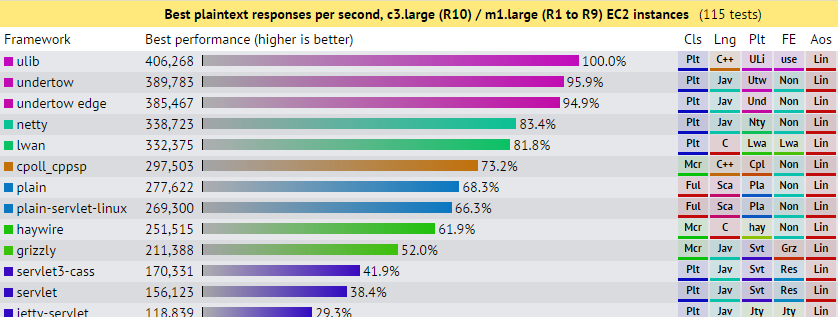
For these TechEmpower benchmarks, the server was run on an Amazon c3.large w/ 2 vCPUs and 3.75GB at $0.188/hr - which looks close enough to an Azure A2 w/ 2 cores and 3.5GB at $0.18/hr. The Azure VM being slightly cheaper; but also having slightly less RAM. So what do we get with the Azure Windows VM? Again, make sure RSS is switched on:
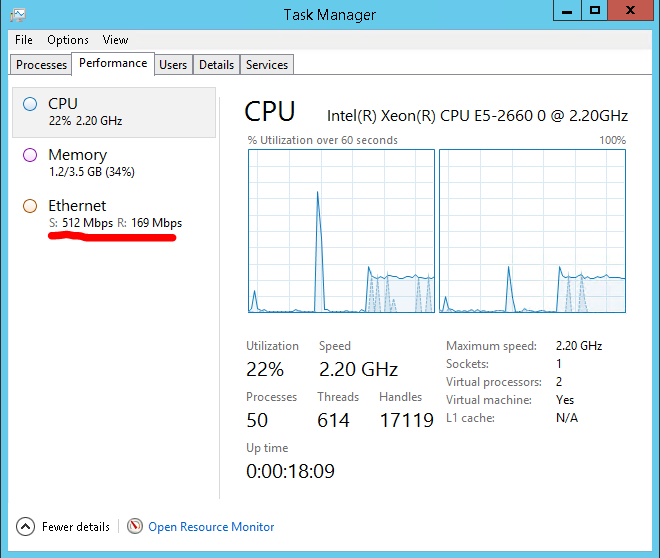
512Mbps using 22% CPU, very respectable and plenty of CPU available. I’m guessing bandwidth capped and split between the VMs on the base hardware; its a fairly small and affordable VM.
What does that equate to? Switching to the linux side to get the requests per second:
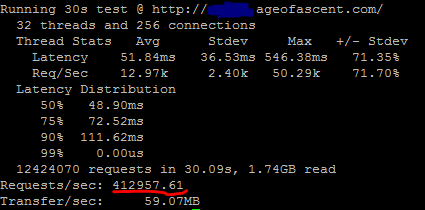
It comes in at 412k requests per second (412,957); which again looking at the chart is some exceptional performance. Latency of 51.8ms (avg), 36.5ms (std-dev), 546ms (max).
Flipping to the latency graph of the TechEmpower tests and including the top 3 “best” servers for throughput gives these results:
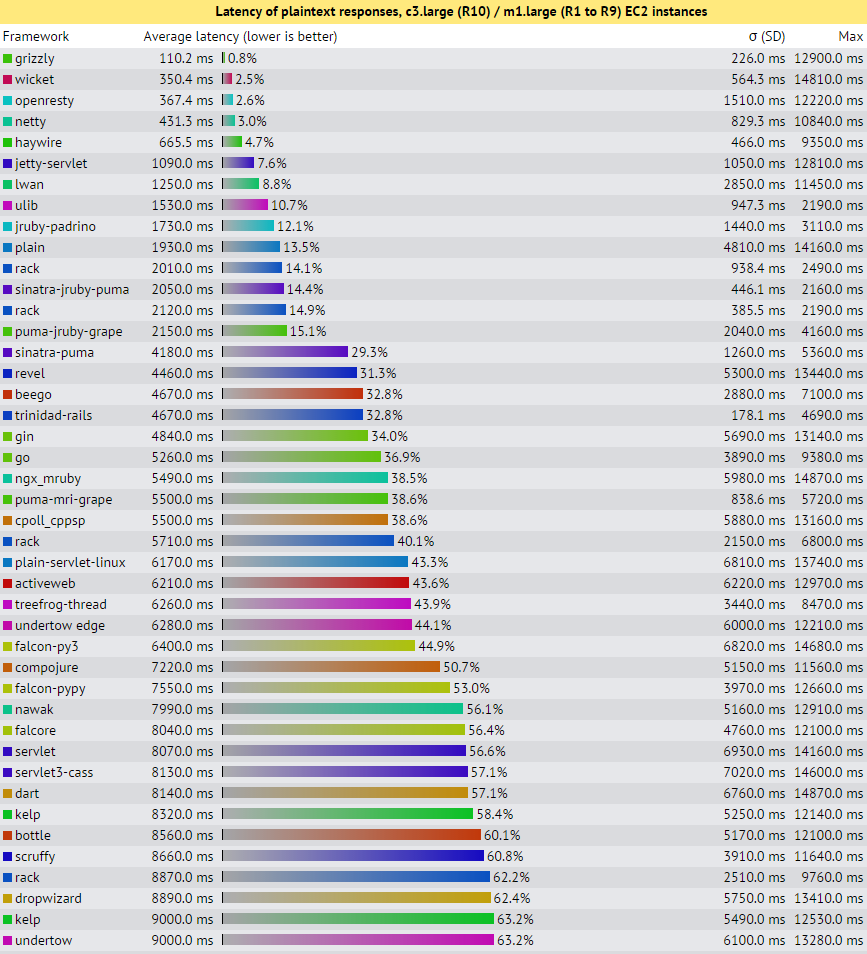
Which I’m not exactly sure how to interpret by comparison…
Looking at a regular website, on a regular current Windows .NET web stack, for our in-progress refresh of our current Grand Strategy MMO – Illyriad:
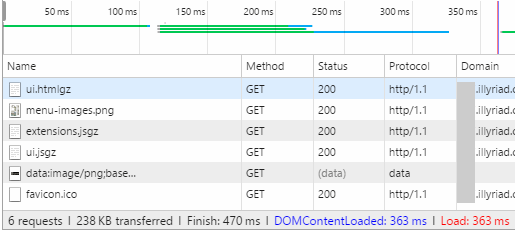
If we can go from an empty cache browser request in Europe to East Coast US and back – twice; a total distance of over 17,400 miles / 28,000km, though load balancers, on regular ASP.NET 4.6 (rather than the leaner newer ASP.NET 5) in the Azure cloud to web page complete for a 238 KB website in under 363ms (favicon.ico ignored); then there is something very, very wrong with those latencies for a simple “Hello, World!” response under 200 bytes; presumably between VMs in the same datacenter! And this is prior to applying of our more recent learnings from this testing, which we shall obviously be doing now!
Can we go bigger (or smaller) in the cloud? On the cheaper end there are the Basic A0-A4 VMs which don’t have all the features of their Standard counterparts A0-A7; and I believe the basic boxes’ CPU are over provisioned; and the A0 in both cases is outright shared CPU.
The D series are my preferred option; D1-D14 have 60% faster CPU than A series; more memory and local SSDs; with D14 being 16 cores 112 GB and 800 GB SSD.
If you are disk bound then there are the DS series; same as D series but with the ability to attach premium storage (RDMA attached SSD) for up to 32 TB and 64,000 IOPS in a RAID configuration w/ > 1ms reads. For our use the DS series and premium storage are great; hence the D4 testing.
However, if your needs are more exotic there are a few other options; for HPC work where you want an explicit CPU rather than a performance guaranteed virtual CPU you can use the A8-A11 VMs with Intel® Xeon® E5-2670 @ 2.6 GHz. The A8/A9 VMs additionally having a 40 Gbps InfiniBand network with RDMA technology, for very fast interconnected clusters.
At the extreme server end, there are G1-G5 with G5 being a 32 core Intel® Xeon® E5 v3 beast with 448 GB RAM and 6144 GB local SSD!
A quick OOTB test between a Windows Azure G4 Virtual Machine and a Linux Azure G4 VM gives these results:
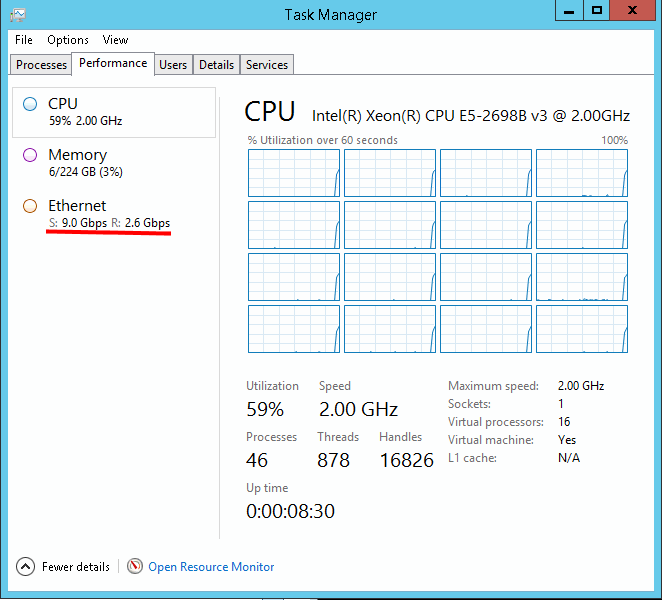
9.0 Gbps at 59% CPU, needs some further multi-core optimizations, looking at the linux wrk server:
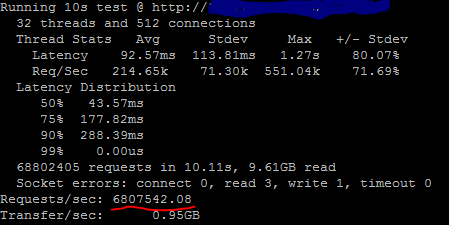
6.8M requests per second (6,807,542). Latency of 92.ms (avg), 113.81 ms (std-dev), 1.27s (max), 50% < 43ms, 90% < 288ms.
However, since this this the cloud, smaller machines will give you better scale in/out granularity - so ymmv depending on what kind of workload you are doing. Also in production, you want to give yourself headroom for bursts, rather than trying to max out your connections - which should also be kinder on latency.
We’re going to continue further testing this setup in a variety of configurations, and will keep you posted on results.
So far, we believe this more than validates that we are not compromising performance by running in Azure, using Windows or managed C# to get both the best performance and also the most developer productivity.
Our take-home learning from these tests so far? If in doubt, measure, measure, measure! And also… even if you think you know, performance is generally lost in unexpected places!
Discus this in our forums: Forum Discussion: Adventures in High Speed Networking on Azure

Get in touch!
For press: press@ageofascent.com.